DiabetesSLM is a Small Language Model fine-tuned on a curated medical Q&A dataset for diabetes, served through a simple web interface on Hugging Face Spaces. The idea was to see how far a small, specialized model could go against a narrow domain — could a fine-tuned Flan-T5-large answer diabetes questions reliably without the cost or latency of a frontier LLM?
Disclaimer: This is an educational demo. It is not medical advice. Anyone with a real health concern should consult a qualified professional.
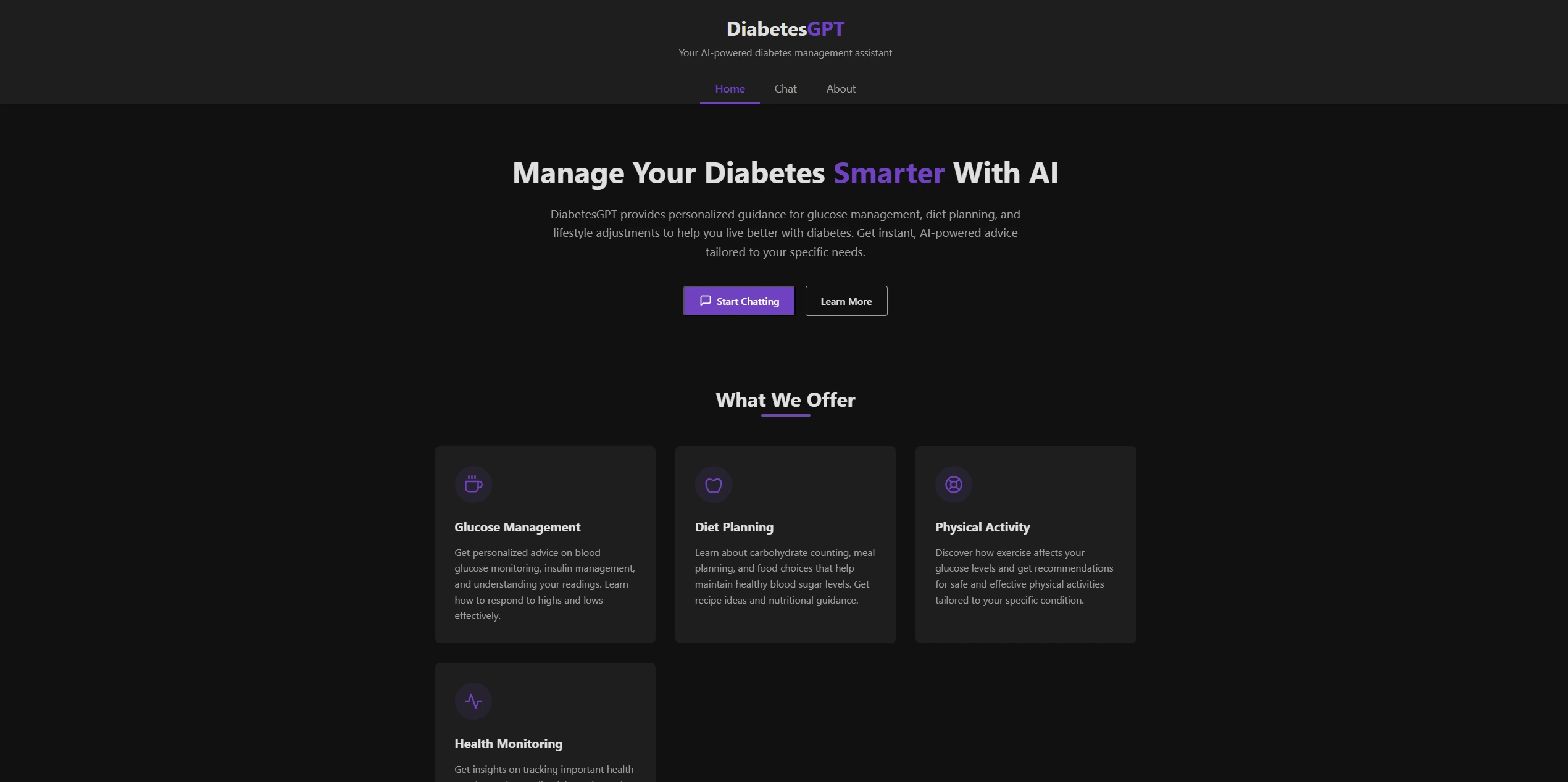
Problem Statement
General-purpose LLMs are good at many things but come with real downsides for narrow applications: they’re expensive to run, can hallucinate confidently outside their training distribution, and require external API calls that make self-hosting or privacy-sensitive deployments difficult. For a focused domain like diabetes Q&A, most of the model’s parameters are doing nothing useful — a smaller, domain-tuned model should be able to serve the same answers with a fraction of the compute.
Solution
I fine-tuned Google’s Flan-T5-large on a custom medical Q&A dataset sourced from the UK’s NHS diabetes content. The resulting model runs comfortably on modest hardware and returns answers in a few hundred milliseconds. It’s wrapped in a small Flask + Gradio app and deployed on Hugging Face Spaces, which handles the serving infrastructure for free.
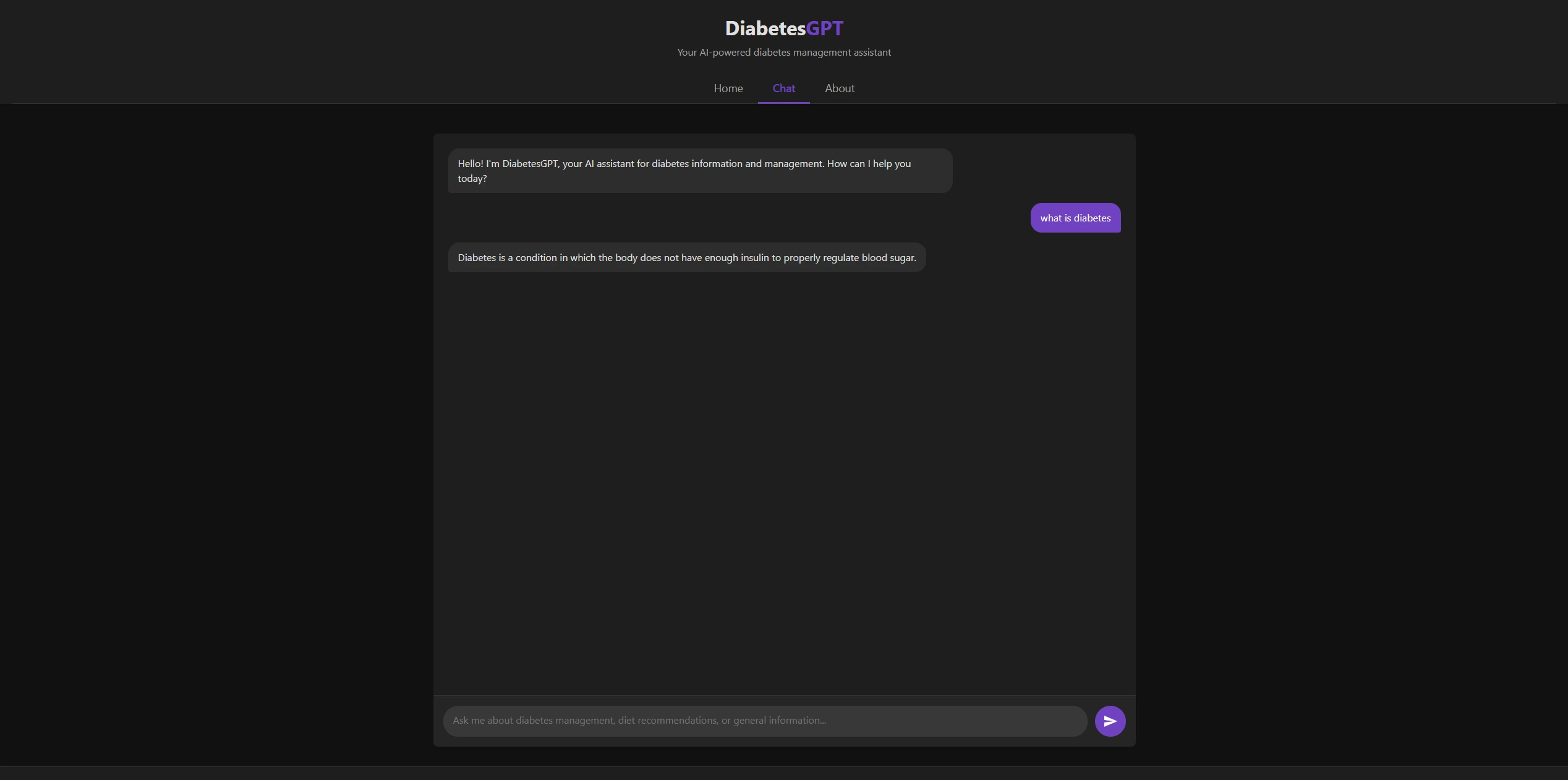
Architecture
- Language: Python throughout — the ML ecosystem is mature here and there’s no good reason to leave it for this stack.
- ML Framework: PyTorch. I didn’t need a framework abstraction layer beyond what
transformersalready provides. - Web Framework: Flask for the backing API, Gradio for the chat UI. Gradio was a fast way to get a usable interface without writing frontend code.
- Core Libraries:
transformersfor loading Flan-T5-large,datasetsfor reading the CSV into a training set,sentencepiecefor tokenization, andacceleratefor the training loop on a single GPU. - Platform: Hugging Face Spaces, free tier. The Space builds from the Git repo on push and serves the model on a CPU instance.
- Version Control: Git + Git LFS. Model weights are too big for regular Git — LFS is the standard here.
- Containerization (optional): A Dockerfile is included if you’d rather run locally or on your own infrastructure.
How it works
- User input: The user types a diabetes-related question into the web interface.
- Frontend (
app.py): Gradio captures the input and passes it to the inference handler. - Model runner (
model_runner.py): Normalizes the input, tokenizes it, and feeds it to the model. - SLM inference: Flan-T5-large generates an answer conditioned on the prompt.
- Response: The decoded answer is returned and rendered in the chat UI.
Features
- Focused Q&A: Answers common diabetes questions drawn from the training set — symptoms, management, diet, complications.
- Small model, fast responses: Fine-tuned Flan-T5-large is small enough to serve on a CPU with sub-second latency for most questions.
- Clear web UI: Gradio chat interface, hosted publicly on Hugging Face Spaces.
- Reproducible: Training script, dataset, and inference runner all in the repo. Someone else can fine-tune their own version in a few hours.
Notable Learnings
Small models punch above their weight in narrow domains
Flan-T5-large has 780M parameters — a tiny fraction of the billions in GPT-class models. After fine-tuning on a focused dataset it’s competitive on the narrow task. The generalization gap showed up the moment I asked it something outside diabetes — it would confidently answer nonsense. Keeping the domain tight is the whole point.
Dataset quality matters more than size
The training set is small — a few thousand Q&A pairs. What it lacks in volume it makes up in consistency: every answer was curated from the same source (NHS), written in the same voice, and structured the same way. That consistency is what the model actually learns. Cramming in more data from varied sources degraded the outputs.
Hugging Face Spaces as a free deploy target
For demos and portfolio projects, Spaces is unmatched. Git push → build → public URL. No servers, no scaling config, no credit card. The free CPU tier is slow for big models but fine for something at this scale.
Limitations I didn’t try to hide
The model hallucinates. It has no knowledge of new research. It can’t handle compound or ambiguous questions well. Rather than paper over these, I documented them in the README and put a clear disclaimer at the top of the UI. A small model pretending to be a doctor is the worst possible failure mode — being honest about what it can’t do is the whole point.
Thank you for reading!